
In the realm of virtual experiences, the creation of realistic and animatable 3D human avatars has long been a challenge. While significant progress has been made in text-to-3D methods, limitations still persist, hindering the ability to generate high-quality and diverse models. However, there is a groundbreaking approach that is revolutionizing the field: DreamHuman. This innovative method generates lifelike and animatable 3D human avatars based solely on textual descriptions. In this blog post, we will delve into the limitations of current text-to-3D methods, explore the innovative approach of DreamHuman, and discover its remarkable capabilities in producing exceptional 3D human models.
Overcoming Limitations: A Need for Progress
Although current text-to-3D methods have made strides in bridging the gap between textual descriptions and 3D models, significant limitations still impede the creation of realistic and diverse avatars. These limitations include restricted control, limited spatial resolution, and the inability to generate animated 3D human models. Additionally, achieving anthropometric consistency for complex structures like human beings remains a considerable challenge.
Introducing DreamHuman: A Paradigm Shift
DreamHuman stands out from the crowd by integrating large text-to-image synthesis models, neural radiance fields, and statistical human body models into a unique modeling and optimization framework. This fusion of cutting-edge technologies enables the generation of dynamic 3D human avatars with lifelike textures and personalized surface deformations.
Unleashing the Power of DreamHuman
One of the most impressive aspects of DreamHuman is its ability to produce a wide variety of animatable and realistic 3D human models based on textual descriptions. These models exhibit diversity in appearance, clothing, skin tones, and body shapes, surpassing generic text-to-3D approaches and previous text-based 3D avatar generators in terms of visual fidelity.
The Inner Workings of DreamHuman
DreamHuman operates by utilizing a given text prompt, such as a detailed description of a woman dressed in a particular attire. Through a meticulous process, DreamHuman generates a 3D avatar that faithfully represents the textual description. A key component of DreamHuman is the incorporation of a deformable and pose-conditioned NeRF model, guided by imGHUM, an implicit statistical model that captures 3D human pose and shape.
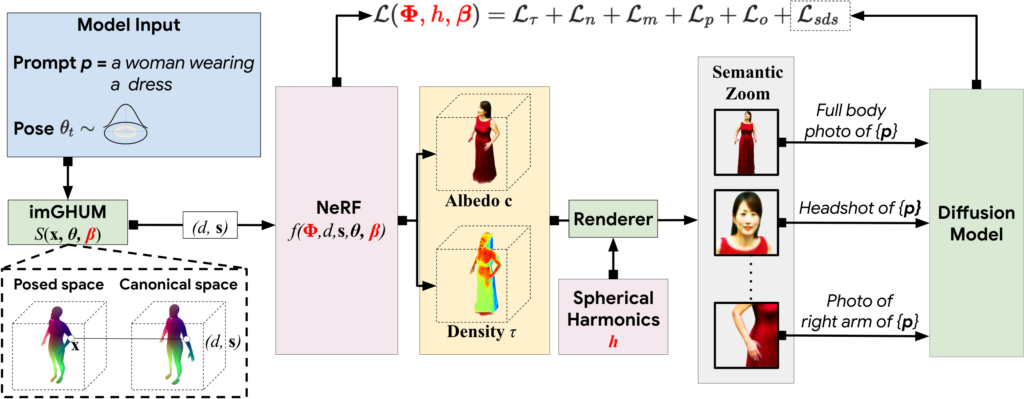
Optimising for Unparalleled Realism
During the training phase, DreamHuman actively samples poses and renders the avatar from various viewpoints to optimize its structure. The optimization process is guided by the Score Distillation Sampling loss, powered by a text-to-image generation model. Furthermore, the inclusion of imGHUM injects precise pose control and anthropomorphic priors, further enhancing the realism of the avatars.
The Path to Realistic Avatars
DreamHuman’s training phase involves meticulous optimization of multiple parameters, including the NeRF model, body shape, and spherical harmonics illumination. This intricate optimization process ensures that the avatars produced possess exceptional quality and accuracy.
Animations
In Conclusion
DreamHuman represents a game-changing technique for generating realistic and animatable 3D human avatar models from textual descriptions. By integrating advanced technologies and employing meticulous optimization processes, DreamHuman sets itself apart from existing methods. With its ability to create diverse avatars surpassing previous approaches, DreamHuman paves the way for immersive and visually stunning virtual experiences. Keep an eye out for more exciting developments in the world of 3D avatar generation with DreamHuman. The future of virtual human representation has never looked more promising.